在线凸优化导论
版权所有。未经作者许可不得转载。
作者:Elad Hazan
ch1 介绍
这篇手稿涉及到最优化是一个过程的观点。在许多实际应用中,环境非常复杂,以至于不可能建立一个全面的理论模型并使用经典算法理论和数学优化。采取一种健壮的方法是必要的,也是有益的,通过应用一种边走边学的优化方法,随着问题的更多方面的观察,从经验中学习。这种将优化作为一个过程的观点已经在各个领域变得突出起来,并在建模和系统方面取得了惊人的成功,这些系统现在已经成为我们日常生活的一部分。机器学习、统计学、决策科学和数学优化的文献不断增长,模糊了确定性建模、随机建模和优化方法之间的经典区别。我们在这本书中延续了这一趋势,研究了一个突出的优化框架,它在数学科学中的确切位置尚不清楚:在线凸优化框架,它最初是在机器学习文献中定义的(参见本章末尾的参考文献)。成功的衡量标准借鉴了博弈论,其框架与统计学习理论和凸优化密切相关。我们欣然接受这些富有成效的联系,并有意不尝试使用任何特定术语。相反,这本书将从可以通过在线凸优化建模和解决的实际问题开始。我们将继续介绍严格的定义、背景和算法。自始至终,我们都提供与其他领域的文献的联系。我们希望您,读者,将从您的专业领域帮助我们理解这些联系,并扩展关于这一引人入胜的主题的不断增长的文献。
1.1 在线凸优化模型(The online convex optimization model)
在在线凸优化中,在线玩家迭代地做出决策。在每一次决策时,与选择相关的结果对玩家来说都是未知的。
在做出决定后,决策者会遭受损失(loss):每一个可能的决定都会导致(可能是不同的)损失(loss)。这些损失(loss)是决策者事先不知道的。损失(loss)可以根据不同的情况选择,甚至取决于决策者所采取的行动。
在这一点上,要想让这个框架有任何意义,有几个限制是必要的:
•不应允许对手确定的损失(loss)是无限制的。否则,对手可能会在每一步上不断减少损失(loss)的规模,并且永远不会让算法从第一步的损失(loss)中恢复过来。因此,我们假设损失(loss)在某个有界区域内。
•决策集必须有一定的界限和/或结构,尽管不一定是有限的。为了理解为什么这是必要的,请考虑具有无限可能决策集的决策。对手可以无限期地为玩家选择的所有策略分配高损失(loss),而将一些策略设置为零损失(loss)。这排除了任何有意义的性能指标。
令人惊讶的是,除了这两个限制之外,还可以派生出有趣的语句和算法。在线凸优化(OCO)框架将决策集建模为欧几里得空间中的凸集,表示为$\mathcal{K}\subseteq \mathbb{R}^{n}$。损失(cost)被建模为$\mathcal{K}$上的有界凸函数。
OCO框架可以看作是一个结构化的重复博弈。该学习框架的协议如下:
在迭代t处,在线玩家选择 $ \mathbf x_{t}\in \mathcal{K} $,当玩家做出这个选择后,就会出现一个凸代价函数(cost function)$f_{t}\in\mathcal{F}:\mathcal{K}\rightarrow\mathbb{R}$。其中,$\mathcal{F}$是对手可用的代价函数(cost function)的有界族。在线玩家产生的成本是$f_{t}(\mathbf x_{t})$,即选择$\mathbf x_{t}$的代价函数的函数值。设T表示游戏迭代的总次数。
怎样才能成为一个好的在线凸优化(OCO)算法?由于该框架本质上是博弈论和对抗性的,因此适当的性能衡量标准也来自博弈论:将决策者的后悔(regret)定义为她所付出的总成本(total cost)与事后(hindsight)看来最好的固定决策(best fixed decision)之间的差额。在OCO中,我们通常对算法最坏情况下后悔的上界感兴趣。
假设$\mathcal{A}$是OCO的算法,它将特定的游戏历史映射到决策集中的决策。我们正式将$\mathcal{A}$在T次迭代后的后悔(regret)定义为: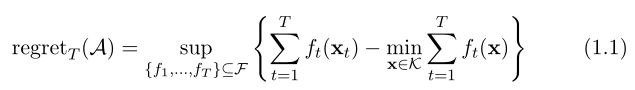
直观地说,如果算法的后悔(regret)是$T$的次线性(sublinear)函数,即 $regret_{T}( \mathcal{A} )=o(T)$,则算法表现良好,因为这意味着该算法在平均水平上表现得与事后最佳固定策略(the best fixed strategy in hindsight)一样好。
算法的运行时间被定义为:在T次迭代重复博弈中,对于迭代$t\in[T]$,产生$ \mathbf x_{t}$的最坏情况期望时间。通常,运行时间将取决于$n$(决策集$\mathcal{K}$的维度)、$T$(游戏迭代的总次数)以及 代价函数(cost function)和底层凸集 的参数。