原文链接及源码链接
原文:https://arxiv.org/abs/1807.07978v3
源码:https://github.com/MadryLab/blackbox-bandits
以前的工作
NES攻击
本文工作
1、证明了NES攻击是自然意义下最优的攻击,将梯度估计问题视为高效查询的黑盒攻击的核心问题 。
2、NES攻击中的梯度估计每次是完全重新估计梯度,本文对此做了改进,利用梯度的先验信息,本文表明了梯度的两类先验信息确实导致了更好的梯度预测。
3、开发了一个基于bandit优化的框架来实现先验信息的无缝集成,用于生成黑盒对抗样本


1、梯度估计问题
将$E[\hat{g}^{T}g^{\star}]$ 中的 $g^{\star}$ 的恢复作为一个欠定向量估计任务。也就是说,我们可以将有限差分法的每次执行视为计算一个内积查询,在这个查询中,我们获得 $g^{\star}$ 的内积值和一些选定的方向向量 $A_{i}$ 。现在,如果我们执行这样的查询,并且$k<d$,则在该过程中获得的信息可以表示为以下(欠定)线性回归问题$Ag^{\star}=y$,其中矩阵$A$的行对应于查询$A_{1},….,A_{k}$,并且向量y的项给我们相应的内积值。
定理1 (NES和最小二乘等价性)进一步地,我们可以利用这种等价性证明[IEA+18]中提出的算法不仅是自然的,而且是最优的,因为最小二乘估计在$k=d$的情况下是信息论上最优的梯度估计,在 $k<<d$ 的情况下是误差最小化的估计。
定理2 (最小二乘最优性(证明见附录A))对于已知 $A$ 和 $y$ 、未知 $g$ ,且为各向异性高斯误差的线性回归问题 $y=A\boldsymbol g$ ,最小二乘估计是在有限样本情况下有效的方法,即潜在向量$g$的最小方差无偏(MVU)估计。
定理3 (最小二乘优化)在欠定情况下,即当k << d时,最小范数最小二乘估计(定理1中的 $\hat x _{LSQ}$ )是无经验损失的最小方差(因此也是最小误差,因为偏差是固定的)估计。
2、梯度的先验信息
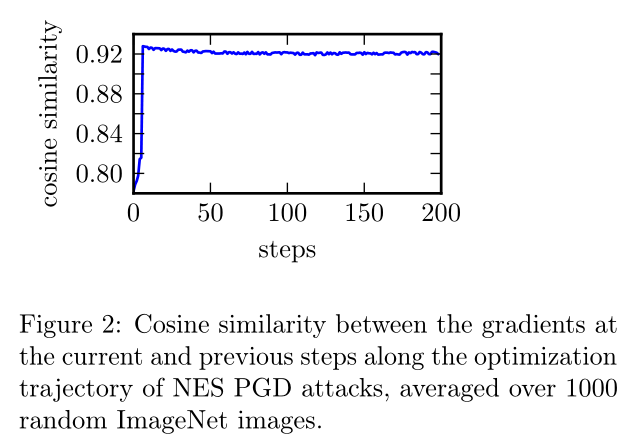
时间相关先验 本文发现,沿着估计梯度所走的轨迹,连续的梯度实际上是高度相关的。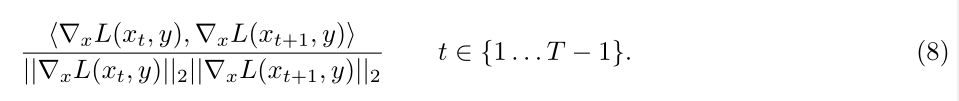
数据相关先验 本文发现还可以使用输入本身的结构来降低查询复杂性
在图像分类的情况下,数据相关先验信息的一个简单且被大量利用的例子源于这样一个事实,即图像倾向于显示空间上的局部相似性(即,邻近的像素往往很相似)。我们发现,这种相似性也延伸到了梯度:具体地说,当$\nabla_{x}L(x,y)$的两个坐标$(i,j)$和$(k,l)$接近时,我们期望$\nabla_{x}L(x,y)_{i,j}$和$\nabla_{x}L(x,y)_{k,l}$也接近。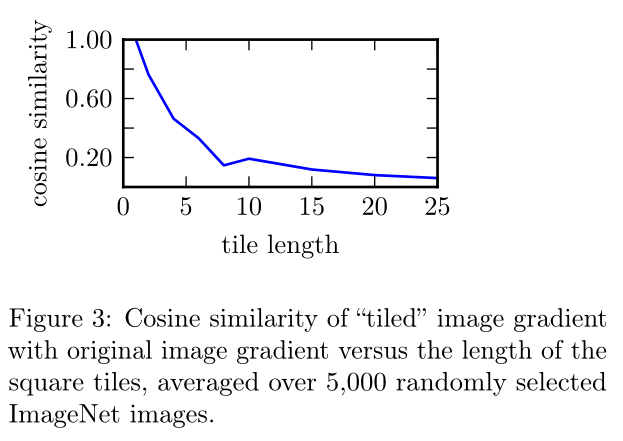
3、Bandit Convex Optimization(BCO)
在bandit优化框架中,代理(agent)玩一个由一系列回合(rounds)组成的游戏(game)。在第$t$回合中,代理必须选择一个有效的动作(action),然后由于执行该动作导致了一个损失,这个损失由损失函数$l_{t}(\cdot)$给出,且代理对这个损失函数未知(所以我们是不能显示地求得损失函数$l_{t}(\cdot)$的梯度的)。在执行完动作后,他/她只知道所选动作造成的损失值(函数值);损失函数是特定于回合$t$的,并且可以在回合之间任意改变。代理人的目标(goal)是将所有回合的平均损失降至最低,代理人的成功通常通过将总损失与事后最好的专家(best expert in hindsight)的损失进行比较来量化(最佳单一行动策略(the best single-action policy))。根据这种公式的性质,这个游戏的各个回合不能被视为独立的—为了很好地执行,代理需要跟踪一些潜在(latent)的记录,这些记录汇总了在一系列回合中学习到的信息。该潜在记录通常采取矢量的形式,该矢量$v_{t}$被约束到指定的(凸)集合$K$。正如我们将看到的,bandit优化框架的这一方面将为我们提供将先验信息合并到我们的梯度预测中的便利方式。
原版 在线凸优化(BCO) 中的reduction from bandit information
虽然不能显示计算$\nabla f_{t}\left(\mathbf{x}_{t}\right)$,但能找到$\nabla f_{t}\left(\mathbf{x}_{t}\right)$的估计量$g_{t}$。

本文对权威的”reduction from bandit information”进行改编,如下所示:
其中,$v_{t}$就是记录学习的潜在向量(latent vector);
$\Delta _{t}$是$l_{t}$的梯度的估计量;
$l_{t}$对player来说是不清楚的,我们(player)只知道这个函数带入自变量之后的函数值,即$l_{t}(g_{t})$;

$\Delta _{t}$是$l_{t}$的梯度的估计量 这个步骤的详细求解如下:

bandit情况下的梯度估计
我们可以相当直接地将梯度估计问题归结为一个bandit优化问题。具体地说,我们假设$t$回合的动作(action)是估计梯度$g_{t}$(基于我们的潜在向量$v_{t}$),损失值$l_{t}$和该预测(梯度)和实际梯度之间的(负)内积相关。注意,我们永远不能直接访问该损失函数$l_{t}$,但是我们能够通过有限差分法(2)估计其在特定预测向量$g_{t}$上的值$l_{t}(g_{t})$,然后通过函数值$l_{t}(g_{t})$求得$l_{t}$的梯度的估计量$\Delta_{t}$。$\Delta_{t}$是bandit框架中用于更新潜在向量$v_{t}$的一个机制,与前面所说的梯度估计问题是没有直接关系的。
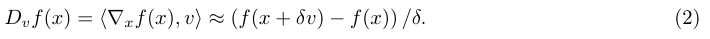

实验结果