Task01
0x01注册Kaggle账号
0x02 跑通baseline
- 播放比赛所提供的训练集中的视频,可以发现
- DeepFake的视频从肉眼上看某些帧人脸会有明显的突变
- 从声音来听,DeepFake的视频大部分都会重复出现
- Baseline思路:单从音频的角度来进行分析视频是否为DeepFake
- Baseline实现方法:提取训练集中音视频的音频信号,对音频信号进行特征提取,将特征送入resnet18模型进行训练
0x03 相关知识点
音频信号的特征提取
语谱图:语音频率随时间变换的情况
MEL-spectrogram(梅尔频谱)
研究表明,人类不会感知线性范围的频率。 我们在检测低频差异方面要胜于高频。 例如,我们可以轻松分辨出500 Hz和1000 Hz之间的差异,但是即使之间的距离相同,我们也很难分辨出10,000 Hz和10,500 Hz之间的差异。
Mel刻度上相等距离的两对频度,人耳的感知差异也是相同的。因此mel谱图是频率转换为mel标度的谱图。
S = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=n_mels) S_dB = librosa.power_to_db(S, ref=np.max)S_dB[i, j] 表示在第i个时间点,在第j个Mel频率段的能量
0x04 需要补充的知识点
- 每个信号都可以分解为一组正弦波和余弦波,它们加起来等于原始信号。
- FFT是全局频域分析
- Window FFT 是时频分析 固定时窗截取变换
- Wavelet transition 是可变长度时窗截取变换
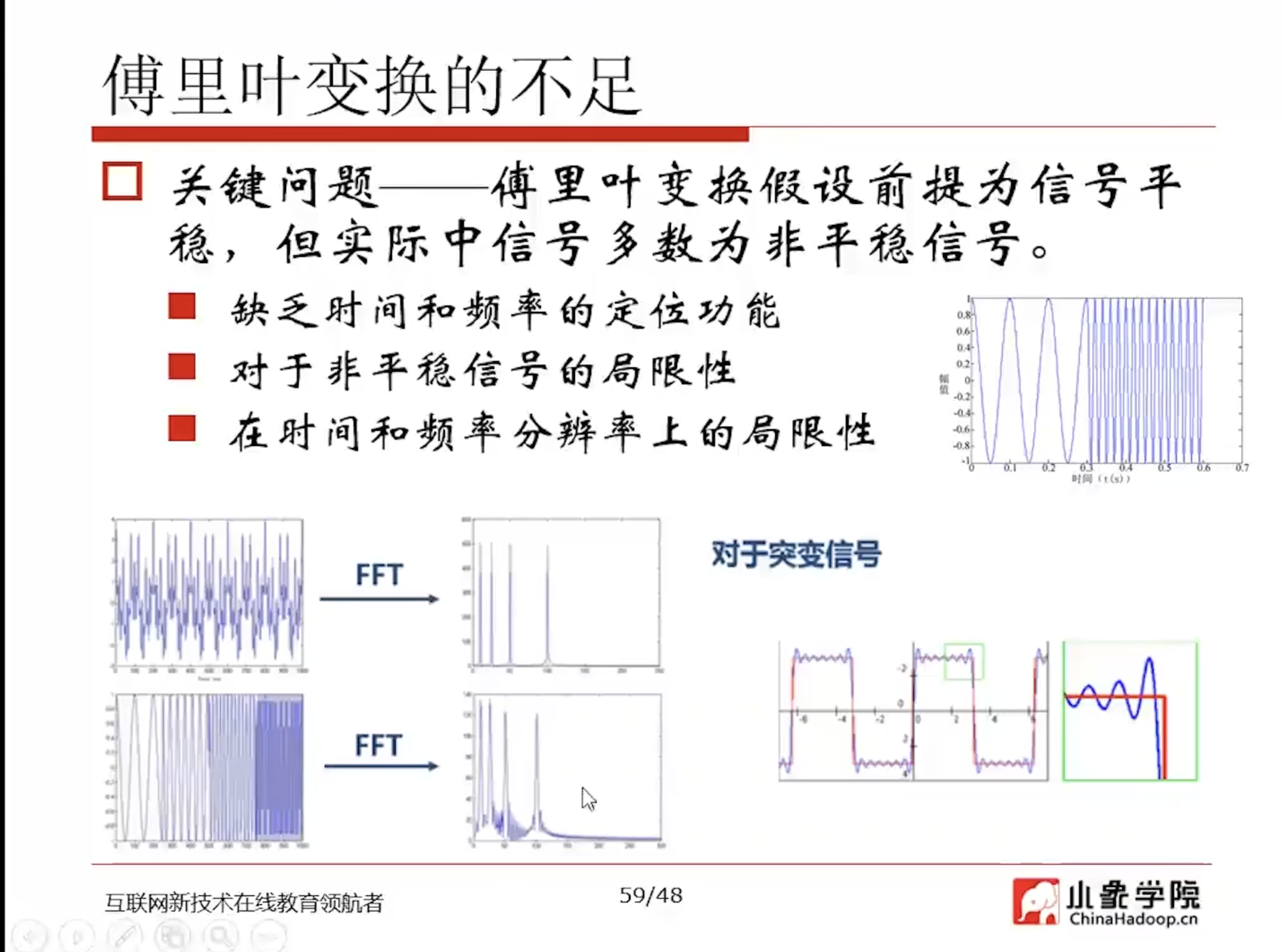
光从频谱上看是不知道原信号长什么样子的
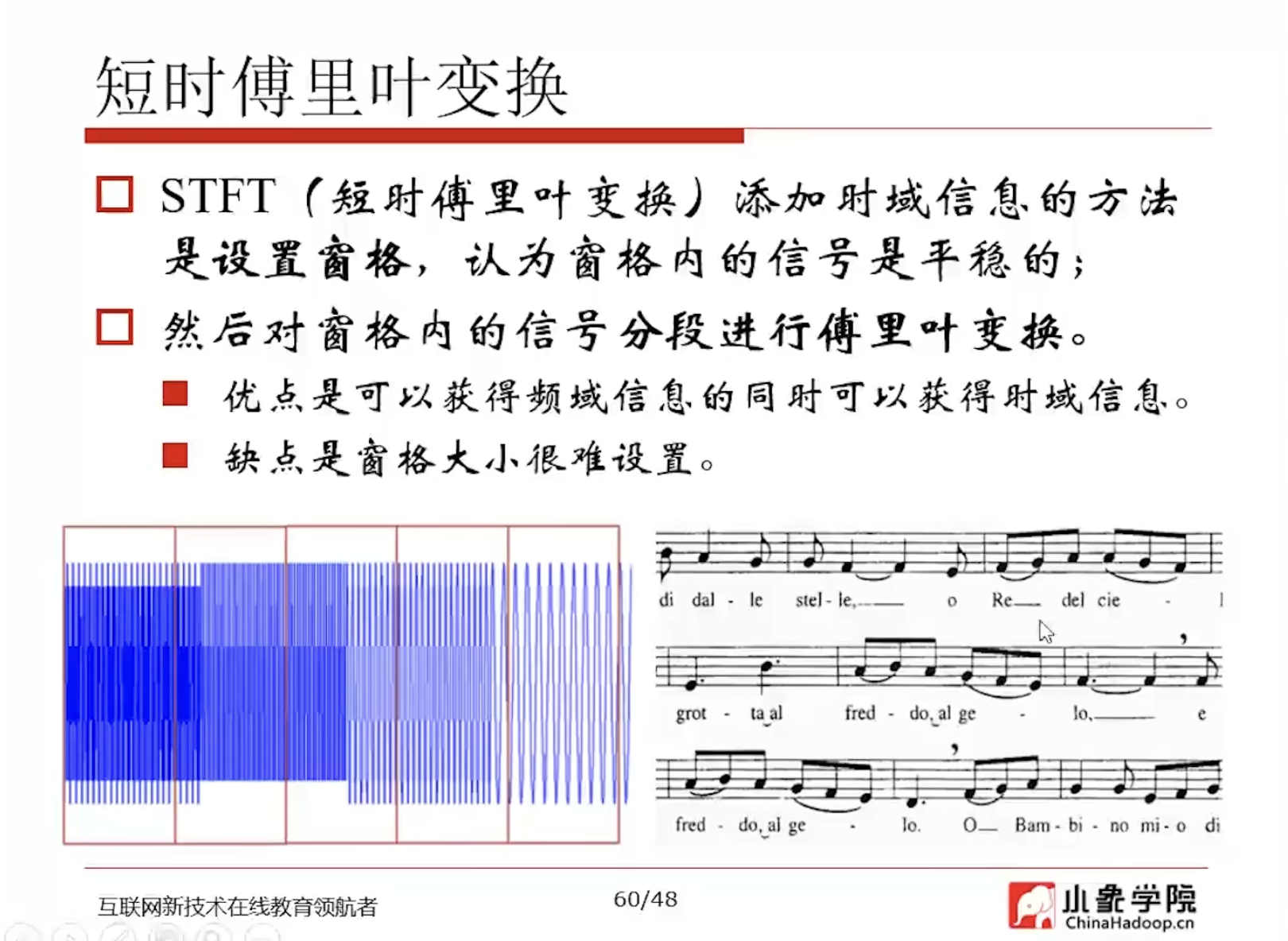
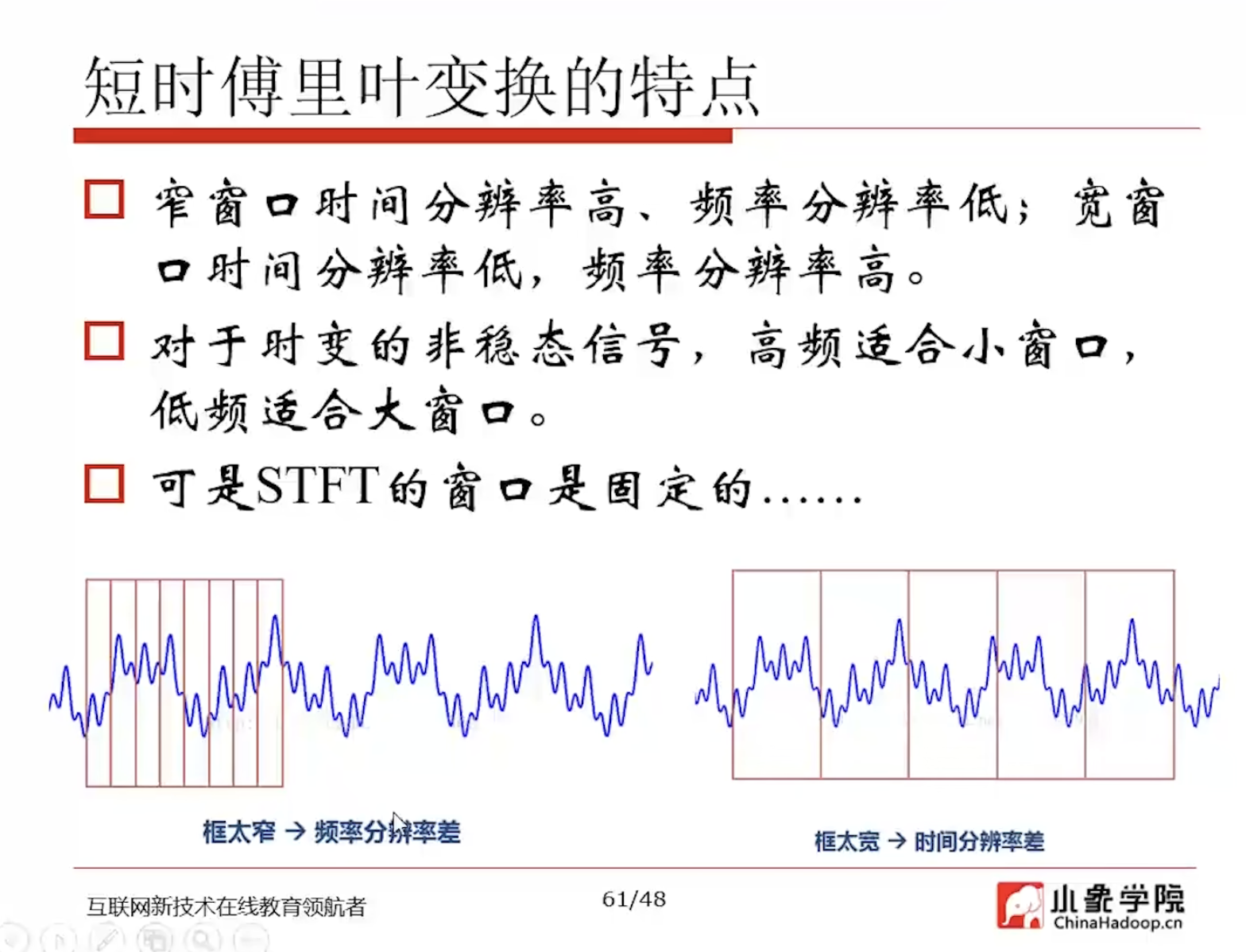
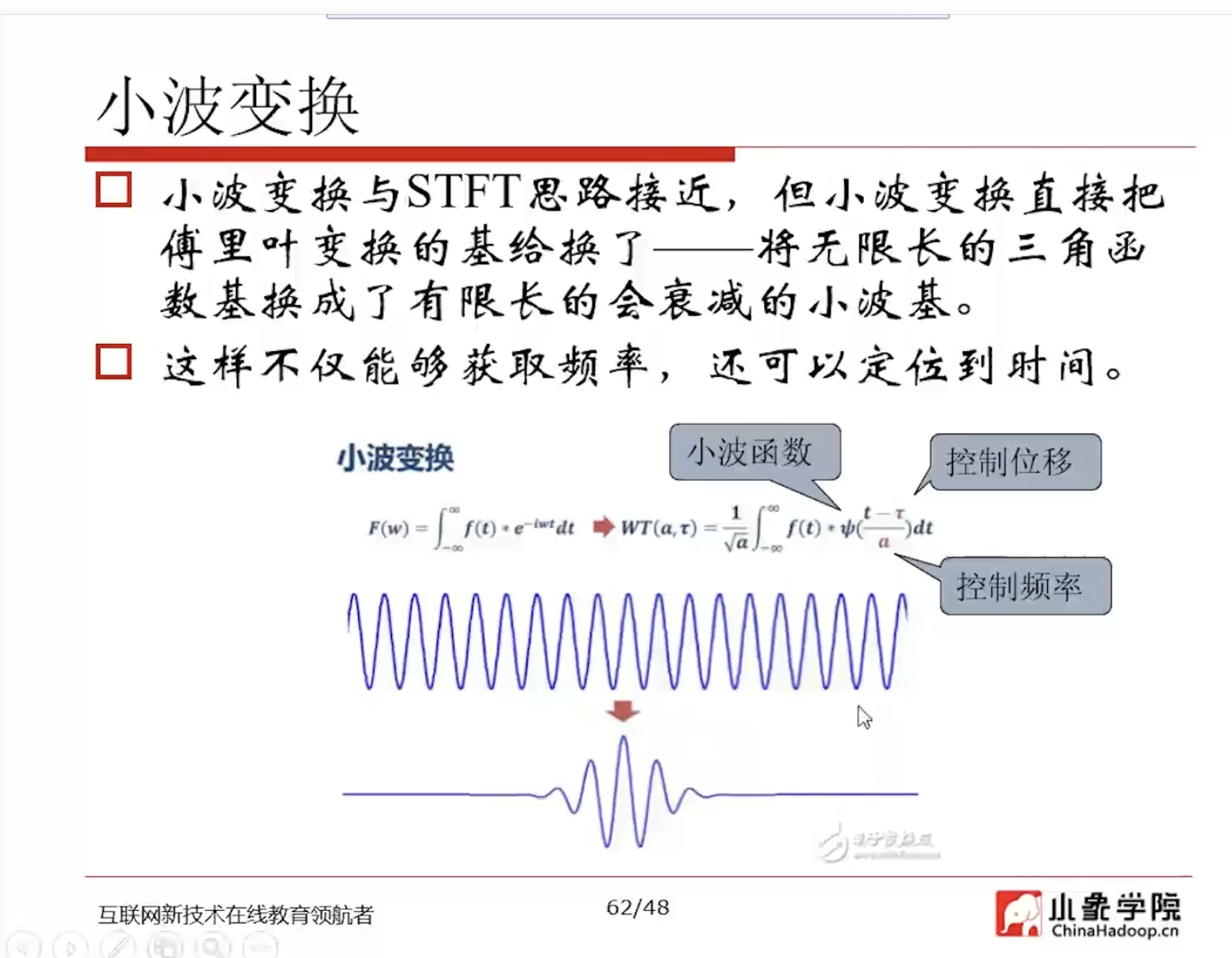
- 梅尔(Mel)量表
研究表明,人类不会感知线性范围的频率。我们在检测低频差异方面要胜于高频。例如,我们可以轻松分辨出500 Hz和1000 Hz之间的差异,但是即使之间的距离相同,我们也很难分辨出10,000 Hz和10,500 Hz之间的差异。
但是人耳感知到的声音高低与声音的原始频率并不呈线性关系,人耳对低频声音更加敏感,低频区域的差异变化比较容易被感受,而对于高频声音的变化感知并不明显。比如10hz和110hz的声音,人耳能够明显感觉到不同,而1000hz和1100hz的声音,人耳感觉会是一样的。频域上相等距离的两对频度,对于人耳来说他们的距离不一定相等。这样的感知是非线性的。
梅尔频谱(Mel spectrogram)是更加符合人耳的听觉特性的一种频域表示法,声音通过一组梅尔滤波器组映射到梅尔音阶上,滤波器在低频范围内分布密集,在高频范围内分布稀疏,Mel谱是非线性的。这样使得在Mel刻度上相等距离的两对频度,人耳的感知差异也是相同的,即人耳感知和梅尔尺度呈线性关系。在低频段(1000hz),梅尔刻度与正常频度几乎呈线性关系,在高频段,两者呈对数关系。
0x05 本地尝试跑baseline
- 数据集太大了,卡在保存MEL特征为jpg图像这一步很久,没往下走了,等它慢慢存完。
0x06 感受
- 还没感受到多模态,现在还只是单一的利用了音频特征,看看后面多模态具体是怎么个多模态法的。
Reference
- Datawhale社区
- https://cloud.tencent.com/developer/article/1689856
- https://www.bilibili.com/video/BV1VY411176K/?spm_id_from=333.999.0.0&vd_source=8915714bbad1ad8be52c5ce9f1bd2f42
- https://www.bilibili.com/video/BV1tu4y1M7th/?spm_id_from=333.337.search-card.all.click&vd_source=8915714bbad1ad8be52c5ce9f1bd2f42
Task02
音频特征提取技术
MFCC
LPCC
FBANK
神经网络结构
也没做了。。。