0x00 原文链接以及源码链接
原文:https://arxiv.org/abs/2106.09667
源码:暂无
摘要
多模态对比学习方法(如CLIP)在含有噪声并且粗糙的训练集上进行训练。这种训练比用人工标注的数据集上训练要便宜,甚至提高了OOD鲁棒性。本文指出这种训练方式容易遭受后门和投毒攻击的威胁。仅仅对数据集中的0.01%的数据进行投毒,我们就能通过覆盖一个小补丁,使模型对测试图像误分类。定向投毒攻击即模型将一个指定输入的图像误分类为敌手渴望的的标签,这个攻击更加简单,仅需要控制数据集中0.0001%的数据(即,300万张图片仅需控制3张)。我们的攻击让人怀疑,在嘈杂和未经处理的互联网上进行训练是否可取。
0x01 引言
Chopra等人的对比学习训练一个模型是将数据分布投影到一个低维的embedding空间,以满足在原始空间相似的对象们在embedding 空间会更接近比原本就不相似的对象们。
在过去几年中取得的重大进展使自监督分类器能够通过对噪声和未经处理的数据集进行训练来达到最先进的精度,这带来了两个显著的好处。
1)首先,对未经处理的数据进行训练更节约成本。与为ImageNet数据集添加标签的估计成本数百万美元相比,经过对比训练的模型无需昂贵的添加标签即可进行训练。此外,由于ImageNet中的每幅图像都需要包含1000个不同对象中的一个,因此有很大类别的图像永远不可能成为该受监管数据集的一部分(?)。另一方面,对比模型可以了解任意图像在某些数据集中是否有合适的对应标签。
2)其次,对噪声数据的训练提高了鲁棒性。专门在ImageNet上训练的分类器覆盖了这个训练集的特定细节,并且不适用于其他测试集。基于互联网数据训练的对比模型表现出令人印象深刻的稳健性;对比训练的CLIP模型是第一个在ImageNet-V2上表现出显著有效稳健性的技术。
贡献
我们提出的理由是,如果即使是很小一部分数据可能被对手恶意下毒,那么对未过滤的数据进行训练可能是不可取的。情况很可能是这样的:在将数据传递给学习算法之前,数据是从互联网上收集的,没有任何人工审查。因此,由于这些数据集显然是“嘈杂的”和“未经管理的”,我们认为至少有一个方面遭到攻击的可能性很高。
我们证明了敌手可以对多模态对比模型发起强大的定向投毒和后门攻击。投毒攻击者将恶意样本放入训练数据集中,使得该模型将在测试时将特定输入错误分类为攻击者期望的标签。然后,我们考虑基于补丁的后门,其中攻击者毒化数据集,以便学习的模型将包含特定触发模式的任何输入分类为期望的目标标签。
现有的攻击足以毒化经过对比训练的模型—尽管我们必须使它们适应这个新领域。
本文的主要贡献是对20,000个GPU小时的经验评估,以表明这些攻击立即实用。使用以前的后门攻击,对用干净标签训练的,平均需要毒化1%的训练数据,我们发现攻击对比模型需要的注入次数减少了数量级:对于许多后门攻击,只需要毒化训练数据的0.01%就足够了,或者对于中毒攻击只需要毒化0.0001%的训练数据。
0x02 方法
Poisoning
目标:一个单一图像$x’$将会在测试阶段被错误分类。
给定目标图像$x’$和期望的目标标签$y’$,首先构造一个和标签$y’$相关的说明文字集$Y’$。例如:如果一张图像的期望标签是“basketball”,那么说明文字集可能会包含文本”A photo of kid playing with a basketball”,定义 poison set $\mathcal{P}$为: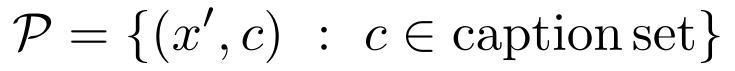
定义 poisoned training dataset为:$\mathcal{X}^{‘}= \mathcal{X} \cup \mathcal{P}$ 。通过增加或者减少说明文字集的大小来控制中毒的样本数量,以便匹配期待的大小。
构建说明文字集:两种方法
法1:给定期待的标签(例如:“basketball”),搜索训练集所有包含这个标签字符串的序列,直接使用这些序列作为说明文字集。
法2:假设额外的攻击者知识。为了产生一个zero-shot classifier,CLIP构建了一组80个不同的“prompt-engineered”文本描述去分类。例如,这些提示里的两个:“a photo of basketball” 或者“a toy basketball”。在这个方法中,直接使用80个提示来构建说明文字集,根据需要使用子集或重复它们,以获得所需的毒物比率。
Backdooring
目标:任意一张带有后门图案$bd$的图像$x$将会被错误分类。
只需要改变poisoning attack中的其中一处,就可以实现backdooring attack。
poisoning attack使用相同的图像$x’$但是配对了不同的说明文字.
backdooring attack对每个中毒的样本使用不同的图像:$x_{i} \oplus bd$。
特别地:定义 poison set $\mathcal{P}$为:$\mathcal{P} = {($x_{i} \oplus bd$), c} : c \in caption set, x_{i} \in \mathcal{X}_{subset}$
构建说明文字集
同样构造了一个包含与感兴趣的下游标签相对应的说明文字集。为了最大限度地减少攻击假设,对于这一部分,不再使用假定知道0-shot提示的说明文字集,而只使用在训练数据集中找到的说明文字。
说人话就是有法1,无法2。
0x03 实验结果
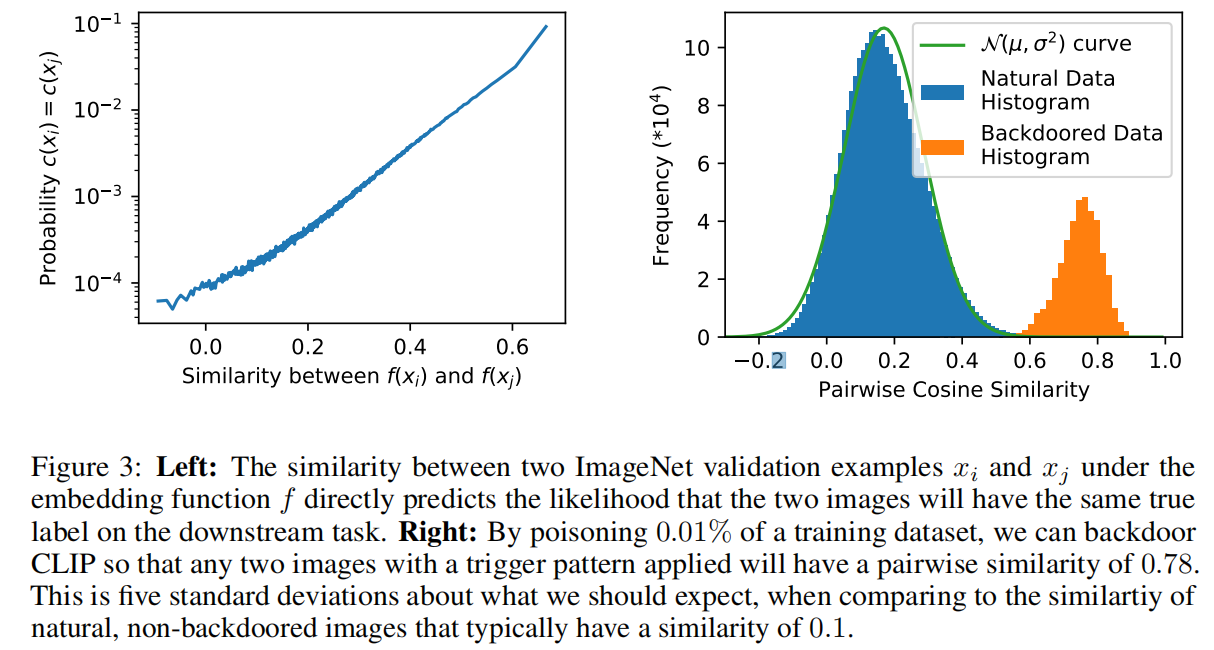
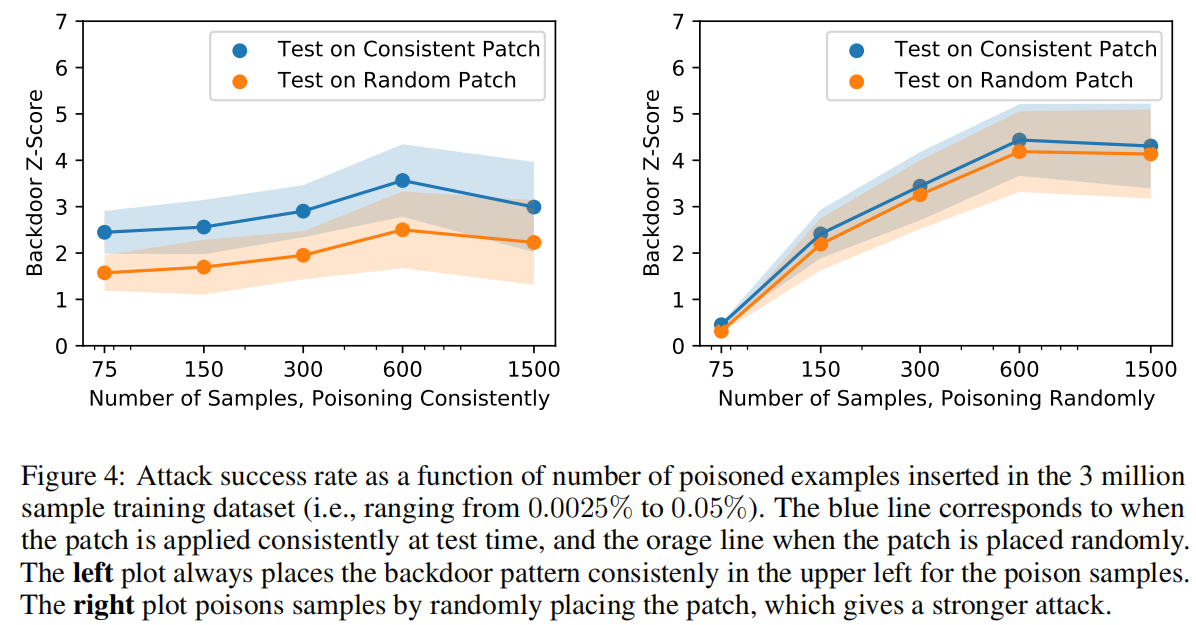
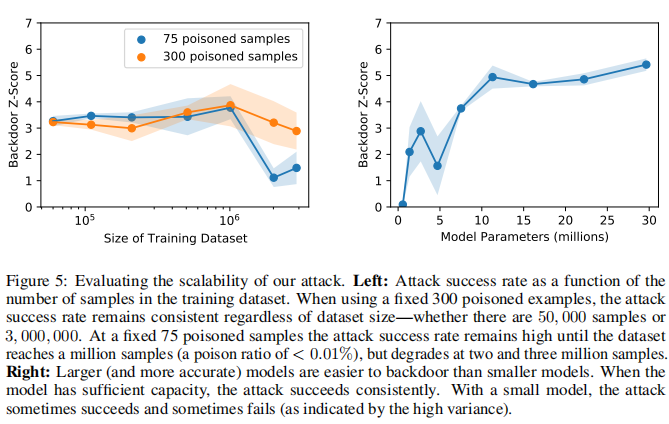
0x04 总结
传统上,机器学习被用于具有精心构建的问题设置的设置(例如,训练模型来标记一些已知的高质量图像),现在在这些设置中工作得很好。然而,精心处理的数据集是昂贵的,并且限制了它们的大小。最新的研究趋势改变了问题设置,要求模型在嘈杂和未经挑选的数据集上学习,这既带来了明显的成本效益,也带来了鲁棒性改进。
本论文证明,在这些未经过滤的数据集上进行训练,虽然现在是可能的,但会增加中毒攻击的风险,尤其是在从互联网上抓取数据时。标准的完全监督中毒攻击必须就攻击者如何将中毒样本注入(人类审查的)数据集中进行复杂的论证。比如对手如何向(人工审查的)数据集中注入有毒样本。另一方面,另一方面,对比学习模型被明确设计为在从公共互联网上收集的嘈杂数据集上进行训练,在这些数据集中,对手可以轻松修改样本。我们认为,随着未来的工作以更嘈杂的数据为基础,减少人类审查,这将增加中毒攻击的可能性和严重性。与完全监督的训练相比,我们的攻击已经需要对训练数据集进行100×更少的修改,正如我们已经表明的那样,扩大数据集并不会降低攻击成功率。这些攻击的存在推动了未来的防御研究。虽然不可能手动审查他们的整个训练数据集(因为这样做会首先删除未经整理的数据上的训练的价值),但这并不排除防御系统试图从训练数据集中过滤恶意中毒样本的可能性。例如,在半监督的情况下,可以监控训练动态以检测是否存在有毒的未标记样本(Carlini,2021),而不需要手动审查未标记的数据集。本篇论文认为,如果要使基于噪声和未经处理的数据进行训练的对比分类器可信,那么开发这些防御措施将是未来工作的一个具有挑战性但极其重要的方向。