原文链接及源码链接
原文:https://arxiv.org/abs/1807.04457
源码:https://github.com/LeMinhThong/blackbox-attack
0x00:前置
g(θ)函数:自变量θ是搜索方向;g(θ)是在取值为θ对应的应变量值,几何意义是:当搜索方向为θ时,对应的到决策边界最近的对抗样本与原图像的距离为g(θ)(失真度)。
./【g1= g(theta_1),自变量和函数值的关系,但在程序中函数值并不是通过带入自变量求得的,而是通过细粒度搜索+二分查找 求得近似函数值】
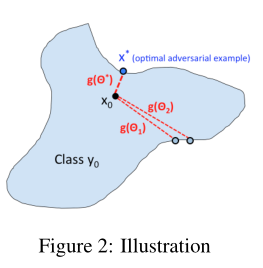
g(θ)将输入方向映射到实值输出(到决策边界的距离),g(θ)通常是连续的!所以可以利用零阶优化方法,这里采用随机无梯度下降RGF。
0x01
- 初始化,1000张图片中找到最小失真(也就是到决策边界的距离,向量的模长)的值g_theta,以及这个失真的方向theta,分别赋值给g_theta和best_theta
0x02
进行随机无梯度下降(RGF)
初始化g2=前面初始化的g_theta;theta=前面初始化的best_theta;min_g1=inf;pre_obj=100000
在1000次迭代里:
part 1:./【 通过10次随机的搜索方向,求梯度,并将这10次随机的搜索方向中 对应的最小失真(到决策边界的距离)保存为 min_g1(距离),该方向保存为min_ttt(方向)。min_g1 = g(min_ttt) 】
循环
随机化一个单位方向:u
ttt = 原单位方向theta+β*随机单位方向u,再单位化 ,这就是新的搜索方向
g1 = g(ttt)的函数值,当方向为ttt时,对应的到决策边界最近的对抗样本与原图像的距离。
梯度:gradient = (g1-g2)/beta * u
如果 新距离g1 < min_g1,更新min_g1=g1;min_ttt=ttt
求这10次的平均梯度gradient
part 2:./【每50次迭代判断结束迭代,退出】
- 如果当前的g(theta)和上一次的g(theta)相差在 stopping =0.01 以内,不再寻找theta
min_theta=theta
min_g2=g2
part 3:./【随机无梯度下降方法(RGF)产生new_theta这个搜索方向,并计算这个搜索方向上的到决策边界的距离new_g2,如果 new_g2 <min_g2 ,即new_theta搜索方向上的距离new_g2比theta搜索方向上的距离小,则更新min_theta,min_g2为new_theta,new_g2】
循环
new_theta = theta - α* gradient,再单位化 ./【RGF】
new_g2 = g(new_theta),通过局部细粒度二分查找获得函数值。
α=α*2
如果新的g2:new_g2<min_g2:更新min_theta=new_theta,min_g2=new_g2,否则结束part3 的循环。./【注:这里是找到比原来大就break了,要是一直比原来小就放大α再往下走,直到15次结束。跨大步找到大的就break】
part 4:./【同part3一样,但α取值不一样】
如果min_g2>=g2,(上面的15次没有进到if判断,而是直接进入else里的break,就会让这里判断为真,进行下面的操作)
循环
α = α*0.25
theta - α* gradient,再单位化
new_g2 = g(new_theta),通过局部细粒度二分查找获得函数值
- 如果新的g2:new_g2<min_g2,即这次产生的new_theta搜索方向的:更新min_theta=new_theta,min_g2=new_g2,并且结束part4的循环。./【注:这里是找到比原来小就break了,要是一直比原来大就把α缩小再往下走,直到15次结束。跨小步找到小的就break。】
part 3 和 part 4 一起 都是在更新min_theta,min_g2。
part 5:./【更新theta,g2。】其中min_g2是通过RGF得到(part3+4)的搜索方向的对应距离,min_g1是随机(part 1)的搜索方向的对应距离。
- 取min_g2和min_g1中的最小者作为新的g2,并将min_g2和min_g1中的最小者的对应的方向赋值给theta。
part 6:./【更新best_theta,g_theta。】part 5 更新的g2是从min_g1和min_g2中选择的最小值,但min_g1和min_g2都不一定会比g_thrta小,所以需要再比较一次,来更新best_theta和g_theta。
- 如果g2 < g_theta:best_theta=theta,g_theta=g2。
part 7:./【best_theta没有改变,则要重置alpha,改变beta】
如果α<1e-4
α=1.0
beta *= 0.01
如果beta<0.0005
- 结束整个迭代
总结
关键在于本篇文章作者定义了一个目标函数g(θ),这个函数将原本的离散决策映射成了一个实值输出(到决策边界的距离)这是连续的!
连续函数的优化问题就要好做很多。
对于只能求函数值而不能求梯度的最佳化问题,可以采用零阶优化方法。本篇文章作者采用的是随机无梯度方法。
改进点:
路径搜索
优化问题