原文链接及源码链接
原文:https://arxiv.org/abs/1807.04457
源码:https://github.com/LeMinhThong/blackbox-attack
摘要
我们研究了在硬标签黑盒(hard-label black-box)环境下攻击机器学习模型的问题,在这种情况下,攻击者除了可以查询探测相应的硬标签决策外,不会显示任何模型信息。这是一个非常具有挑战性的问题,因为将最先进的白盒攻击(例如,C&W或PGD)直接扩展到硬标签黑盒设置将需要最小化非连续阶跃函数,该阶跃函数是组合的,并且不能通过基于梯度的优化器来解决。目前唯一的方法是基于边界上的随机游走[1],这需要大量的查询,并且缺乏收敛性保证。我们提出了一种新的方法,将硬标签黑盒攻击描述为一个实值优化问题,该问题通常是连续的,可以用任何零阶优化算法来求解。例如,使用随机化的无梯度方法[2],我们能够限制我们的算法获得驻点所需的迭代次数。我们在MNIST、CIFAR和ImageNet数据集上证明了我们的方法比以前的随机游走方法更好地攻击卷积神经网络。更有趣的是,我们证明了该算法还可以用来攻击其他离散和非连续的机器学习模型,如梯度增强决策树(GBDT)。
引言
最近有人观察到,机器学习算法,特别是深层神经网络,容易受到对抗样本的攻击。例如,在图像分类问题中,攻击算法[9,3,10]可以为几乎所有图像找到对抗的例子,只要有人类无法察觉的微小扰动。找到一个对抗样本的问题可以被看作是解决一个最优化问题—在原始样本周围的一个小邻域内,找到一个点来优化衡量攻击“成功”的代价函数。使用基于梯度的优化器求解此目标函数会导致最先进的攻击。
大多数当前的攻击考虑的是“白盒”设置,即机器学习模型完全暴露给攻击者。在该设置中,可以通过反向传播来计算上述攻击目标函数的梯度,因此可以非常容易地进行攻击。当攻击者不知道模型参数时,这种白盒设置显然是不现实的。取而代之的是,最近的几篇文章考虑了“基于分数的黑盒”设置,其中机器学习模型对攻击者来说是未知的,但可以进行查询以获得模型的相应概率输出。然而,在许多情况下,真实世界模型不会向用户提供概率输出。取而代之的是,只能观察到最终决定(例如,前1个预测类别)。因此,展示机器学习模型在这种设置下是否易受到攻击是很有趣的。
此外,现有的基于梯度的攻击不能应用于一些涉及离散决策的非连续机器学习模型。例如,基于决策树的模型(随机森林和梯度增强决策树(GBDT))的稳健性不能使用基于梯度的方法来评估,因为这些函数的梯度不存在。
在本文中,我们开发了一个基于优化的框架,用于在更现实、更通用的“硬标签黑盒”环境下攻击机器学习模型。我们假设模型没有被暴露,攻击者只能进行查询来获得相应的硬标签决策,而不是概率输出(也称为软标签)。在这种情况下的攻击非常具有挑战性,之前几乎所有的攻击都失败了,原因有两个。首先,梯度不能通过反向传播直接计算,基于有限差分的方法也会失败,因为硬标签输出对小的输入扰动不敏感;其次,由于只观察到硬标签判决,攻击目标函数变得不连续,输出是离散的,这本质上是组合的(?没明白?原文: which is combinatorial in nature and hard to optimize ),很难优化(更多细节见第2.4节)。
在本文中,我们通过将硬标签黑盒攻击转化为一个新的实值优化问题,使硬标签黑盒攻击成为可能并提高查询效率,实值优化问题通常是连续的且更容易解决。虽然这种重构的目标函数不能写成解析形式,但我们展示了如何使用模型查询来评估其函数值,并应用任何零阶优化算法来解决它。此外,我们证明了只要边界光滑,通过仔细控制函数计算的数值精度,随机无梯度(RGF)方法可以收敛到固定点。我们注意到,这是第一次在硬标签黑盒设置中保证收敛速度的攻击。在实验中,我们展示了该算法能够成功地在MNIST、CIFAR和ImageNet上对硬标签黑盒CNN模型进行攻击,而查询次数要少得多。
此外,由于我们的算法不依赖于分类器的梯度,我们可以将我们的方法应用于除神经网络之外的其他不可微分类器。我们展示了一个有趣的应用,在攻击梯度增强决策树(GBDT)时,即使在白盒环境下,梯度增强决策树(GBDT)也不能被所有现有的基于梯度的方法攻击。但是,对于GBDT(梯度增强决策树),我们的方法可以在3万个查询中成功地找到具有不可察觉扰动的对抗性样本 。
2 背景及相关工作
我们将首先介绍我们的问题设置,并给出一个简短的文献回顾,来强调攻击硬标签黑箱模型的难度。
2.1 问题设置
为简单起见,本文考虑攻击K-Way多类分类模型。给定分类模型 $f: \mathbb{R}^{d} \rightarrow\{1, \ldots, K\}$ 和原始图像$\boldsymbol{x}_{0}$,我们目标是生成一个对抗样本$\boldsymbol{x}$,但是$\boldsymbol{x}$与原始图像$\boldsymbol{x}_{0}$很接近,而且$f(\boldsymbol{x}) \neq f\left(\boldsymbol{x}_{0}\right)$,也就是说是的对抗样本的分类结果与原始图像的分类结果不一致,即对抗样本被模型错误分类了。
$\boldsymbol{x}$ is close to $\boldsymbol{x}_{0}$ and $f(\boldsymbol{x}) \neq f\left(\boldsymbol{x}_{0}\right)$,($x$ is misclassified by model $f$) (1)
2.2 白盒攻击
文献中的大多数攻击算法都考虑白盒设置,即分类器$f$暴露给攻击者。对于神经网络,在此假设下,由于攻击者已知网络结构和权值,因此可以对目标模型进行反向传播。
对于神经网络中的分类模型,经常假设$f(\boldsymbol{x})=\operatorname{argmax}_{i}\left(Z(\boldsymbol{x})_{i}\right)$,其中$Z(\boldsymbol{x}) \in \mathbb{R}^{K}$ 是最后(Logit)一层的输出,$Z(\boldsymbol{x})_{i}$ 是第i 类的预测得分。然后(1)中的问题可以自然而然地表示为以下优化问题:
$\underset{x}{\operatorname{argmin}}\left\{\operatorname{Dis}\left(\boldsymbol{x}, \boldsymbol{x}_{0}\right)+c \mathscr{L}(Z(\boldsymbol{x}))\right\}:=h(\boldsymbol{x})$, (2)
其中$\operatorname{Dis}(\cdot, \cdot)$ 是某种距离度量(例如:欧几里得空间中的$\ell_{2}$、$\ell_{1}$和$\ell_{\infty}$范式),$\mathscr{L}(\cdot)$是对应于攻击目标的损失函数,$c$是一个平衡参数。对于非定向攻击,其目标是使目标分类器错误分类,损失函数可以定义为:
$\mathscr{L}(Z(\boldsymbol{x}))=\max \left\{[Z(\boldsymbol{x})]_{y_{0}}-\max _{i \neq y_{0}}[Z(\boldsymbol{x})]_{i},-\kappa\right\}$, (3)
其中$\boldsymbol{y}_{0}$是被分类器预测的原始标签。对于定向攻击,攻击的目的是转变为特定目标类,也可以相应地定义损失函数。
因此,攻击机器学习模型可以假设为求解这个优化问题,根据距离度量的选择,也称为C&W攻击或EAD攻击。要求解(2),可以应用任何基于梯度的优化算法,例如SGD或ADAM,因为 $\mathscr{L}(Z(\boldsymbol{x}))$的梯度可以通过反向传播来计算。
计算梯度的能力还可以在白盒设置中实现多种不同的攻击。例如,方程(2)也可以转化为约束优化问题,然后用投影梯度下降法(PGD)求解。FGSM是具有$\ell_{\infty}$范数距离的一步PGD的特例。其他算法,如Deepfool,也可以解决类似的优化问题来构造对抗性示例。
2.4 以前关于黑盒攻击的工作
在现实世界的中,通常不会暴露底层的机器学习模型,因此不能应用白盒攻击。这促进了在黑盒环境下攻击机器学习模型的研究,在黑盒环境下,攻击者没有关于函数$f$的任何信息,唯一有效的操作是查询模型并得到相应的输出$f(\boldsymbol{x})$。黑盒攻击的第一种方法是使用转移攻击,而不是攻击原始模型$f$,攻击者试图构建替代模型$\hat{f}$来模仿$f$,然后使用白盒攻击方法攻击$\hat{f}$。这种方法得到了很好的研究和分析。然而,最近的论文表明,攻击替代模型通常会导致更大的失真和低成功率。因此,取而代之的是,[10]考虑了基于分数的黑盒设置,其中攻击者可以使用$x$来查询Softmax层输出以及最终分类结果。在这种情况下,只要目标函数$h(\boldsymbol{x})$对于任何$x$存在,他们就可以重构损失函数(3)并对其进行评估。因此,可以直接应用零阶优化方法来最小化$h(\boldsymbol{x})$。[16]通过引入两个新的构件,进一步提高了[10]的查询复杂度:(i)一种平衡查询计数和失真的自适应随机梯度估计算法;(ii)一种训练有素的自动编码器,可实现攻击加速。[13]利用进化算法解决了一个基于分数的攻击问题,表明该方法同样适用于硬标签黑盒设置。
2.4 硬标签黑盒攻击难度
在本文中,硬标签黑盒设置指的是现实世界中的ML系统只提供输入查询的有限预测结果的情况。具体地说,攻击者只知道最终判决(TOP-1预测标签)而不是概率输出。
在这种情况下进攻是非常具有挑战性的。在图1a中,我们显示了一个简单的三层神经网络的决策边界。请注意,$\mathscr{L}(Z(\boldsymbol{x}))$项是连续的,如图1b所示,因为Logit层输出是实值函数。但是,在硬标签黑盒设置中,只有$f(\cdot)$而不是$Z(\cdot)$可用。由于$f(\cdot)$只能是one-hot向量,如果将$f$带入损失函数,则$\mathscr{L}(f(\boldsymbol{x}))$(如图1c所示)将是不连续的并且具有离散的输出。
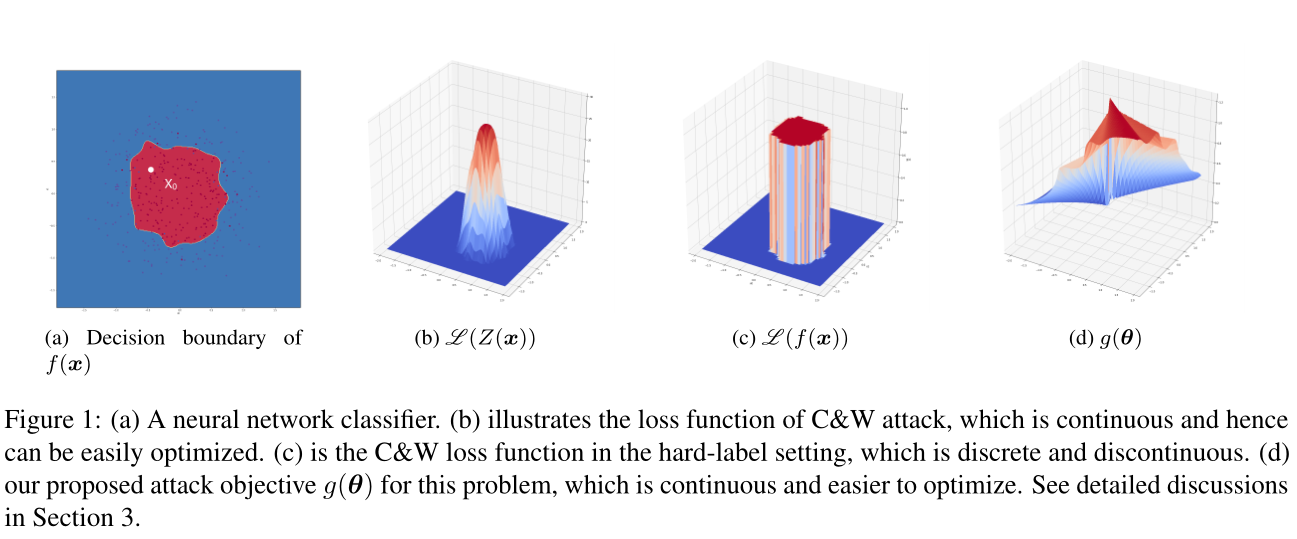
优化这个函数$\mathscr{L}(f(\boldsymbol{x}))$将需要组合优化或搜索算法,这在高维情况下几乎是不可能做到的。因此,文献中几乎没有一种算法能够成功地进行硬标签黑盒攻击。目前唯一的方法[1]是基于边界上的随机游走。
虽然这种基于决策的攻击可以找到与白盒攻击相当的失真对抗性样本,但是它的搜索时间是指数级的,导致大量查询,并且缺乏收敛保证。实验结果表明,与基于决策的攻击相比,基于优化的算法可以显著减少查询次数,并且保证了迭代次数(查询)的收敛性。
3 算法
现在我们将介绍一种新的方法来重新制定硬标签黑盒攻击作为另一个优化问题,展示如何使用硬标签查询来计算函数值,然后应用零阶优化算法来求解。
3.1 基于边界的重新公式化
对于一个给定的样本$\boldsymbol{x}_{0}$、真实的标签$\boldsymbol{y}_{0}$、硬标签黑盒函数$f: \mathbb{R}^{d} \rightarrow\{1, \ldots, K\}$,我们根据攻击类型定义了目标函数$g: \mathbb{R}^{d} \rightarrow\R$
Untargeted attack: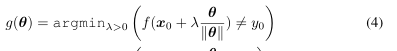
Targeted attack: 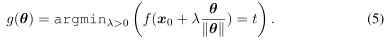
在该公式中,$\theta$表示搜索方向,$g(\theta)$是沿$\theta$方向从 $\boldsymbol{x}_{0}$到最近的对抗性样本的距离。(4)和(5)的区别在于对非目标攻击和目标攻击中“成功”的不同定义,前者的目的是把预测变成任何错误的标签,而后者的目的是把预测变成指定目标的标签。对于无目标攻击,$g(\theta)$也对应于沿$\theta$方向到决策边界的距离。在图像问题中,$f$的输入域是有界的,因此我们将在(4)和(5)的定义中添加相应的上下界。
我们不搜索对抗性样本,而是搜索方向$\theta$来最小化失真(θ),这导致了以下优化问题:

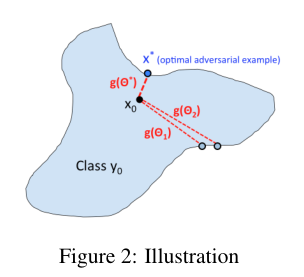
最后,通过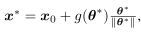 ,其中$\theta*$是(6)的最优解。请注意,与C&W或PGD目标函数不同,C&W或PGD目标函数在硬标签设置中是不连续的阶跃函数(见第2节),$g(\theta)$将输入方向映射到实值输出(到决策边界的距离),这通常是连续的,$\theta$的微小变化通常会导致$g(\theta)$的微小变化,如图2所示。
,其中$\theta*$是(6)的最优解。请注意,与C&W或PGD目标函数不同,C&W或PGD目标函数在硬标签设置中是不连续的阶跃函数(见第2节),$g(\theta)$将输入方向映射到实值输出(到决策边界的距离),这通常是连续的,$\theta$的微小变化通常会导致$g(\theta)$的微小变化,如图2所示。
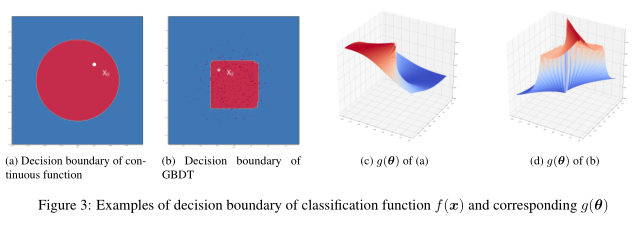
此外,我们还给出了定义在二维输入空间中的$f(x)$及其对应的$g(θ)$的三个例子。在图3a中,我们有如下定义的连续分类函数:
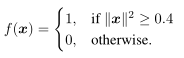
在这种情况下,如图3c所示,$g(θ)$是连续的。此外,在图3b和图1a中,我们显示了GBDT和神经网络分类器生成的决策边界,这两个边界不是连续的。然而,如图3d和图1d所示,即使分类器函数不是连续的,g(θ)仍然是连续的。这使得应用零阶法求解变得容易(6)。
计算$g(θ)$达到一定的精度。我们不能计算g的梯度,但我们可以对原始函数$f$使用硬标签查询来计算g的函数值。为简单起见,我们在这里重点讨论非定向攻击,但同样的过程也可以应用于定向攻击。
首先,我们讨论了如何在没有附加信息的情况下直接计算$g(θ)$。这在我们的算法的初始化步骤中使用。对于给定的规范化$θ$,我们先进行细粒度搜索(fine-grained search),然后进行二分查找(binary search)。在细粒度搜索中,我们逐个查找点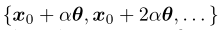 ,直到找到
,直到找到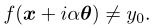 。这意味着边界在
。这意味着边界在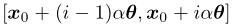 之间。然后我们进入第二阶段,执行二分查找来在该区域内找到解(与算法1中的第11-17行相同)。
之间。然后我们进入第二阶段,执行二分查找来在该区域内找到解(与算法1中的第11-17行相同)。
接下来,我们讨论当我们知道解非常接近于值v时,如何计算$g(θ)$。这在我们的优化算法中的所有函数求值中使用,因为当前解通常与前一个解接近,并且当我们使用(7)估计梯度时,查询的方向将只是前一个方向的一个小扰动。在这种情况下,我们首先增加或减少局部区域,以找到包含边界(例如,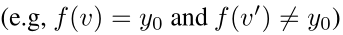 )的区间,然后进行二分搜索以求出g的最终值。我们的计算g值的过程在算法1中给出。
)的区间,然后进行二分搜索以求出g的最终值。我们的计算g值的过程在算法1中给出。


3.2 零阶优化
对于只能求函数值而不能求梯度的最佳化问题,可以自然地应用零阶优化算法。事实上,在重新构造之后,任何零阶优化算法都有可能解决这个问题,比如零阶梯度下降法或坐标下降法(详见文献[17])。
在这里,我们建议使用文献[2,18]中提出的随机无梯度(RGF)方法来求解方程(1)。在实践中,我们发现它的性能优于零阶坐标下降。在每次迭代中,梯度由以下公式估计

其中,$u$是随机高斯变量,$\beta>0$是平滑参数(我们在所有实验中都设置了β=0.005)。然后用步长$η$由$\boldsymbol{\theta} \leftarrow \boldsymbol{\theta}-\eta \hat{\boldsymbol{g}}$更新该解。在算法2中对整个过程进行了总结:

当我们应用该算法时,有几个实现细节。首先,对于高维问题,我们发现(7)中的估计是非常噪声的。因此,我们不使用一个向量,而是从高斯分布中抽样q个向量,并对它们的估计量进行平均,以得到$\hat{g}$。我们在所有的实验中都设置q=20。收敛性证明自然可以推广到这种情况。其次,我们不使用固定的步长(理论上建议),而是使用回溯直线搜索法(backtracking
line-search approach)(见补充)来求出每一步的步长。这会导致额外的查询计数,但会使算法更加稳定,并且不需要手动调整步长。
3.3 理论分析
如果$g(\theta)$可以精确计算,[2]中已经证明了算法2中的RGF需要至多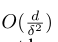 次迭代才能收敛到
次迭代才能收敛到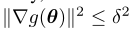 ,然而,在我们的算法中,函数值$g(\theta)$不能精确计算,在算法1中,我们可以通过二进制阈值来控制精度。因此,我们将[2]中的证明扩展到包括近似函数值计算的情况,如下面的定理所述。
,然而,在我们的算法中,函数值$g(\theta)$不能精确计算,在算法1中,我们可以通过二进制阈值来控制精度。因此,我们将[2]中的证明扩展到包括近似函数值计算的情况,如下面的定理所述。
定理 1 在算法2中,假设g是具有常数$L_{1}(g)$的Lipschitz-连续梯度,如果函数值得计算误差由$\epsilon$~$O(\beta\delta^{^{2}})$和$\beta$~$O(\frac{\delta}{dL_{1}(g)})$控制,那么为了获得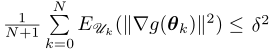 ,总的迭代次数至多为$O(\frac{d}{\delta^{2}})$。
,总的迭代次数至多为$O(\frac{d}{\delta^{2}})$。
详细的证明可以在附录中找到。请注意,二分查找过程可以在$O(log\delta)$步内获得所期望的函数值精度,利用与定理1相同的思想并遵循[2]中的证明,当$g(\theta)$不平滑但 Lipschitz连续的时候,我们也可以达到$O(\frac{d^{2}}{\delta^{3}})$的复杂度。
4 实验结果
我们在卷积神经网络(CNN)模型上测试了我们的硬标签黑盒攻击算法的性能,并与基于决策的攻击算法[1]进行了比较。此外,我们还证明了我们的方法可以应用于攻击梯度提升决策树(GBDT),并给出了一些有趣的发现。
4.1攻击CNN图像分类模型
我们使用三个标准数据集:MNIST[19]、CIFAR-10[20]和ImageNet-1000[21]。为了与以前的工作进行公平的比较,我们采用了[9]和[1]中使用的相同网络。详细地说,MNIST和CIFAR都使用相同的网络结构,具有四个卷积层、两个最大池层和两个全连通层。使用[9]提供的参数,我们可以在MNIST上达到99.5%的准确率,在CIFAR-10上达到82.5%的准确率,这与文献[9]中报道的结果相似。对于Imagenet-1000,我们使用了Torchvision提供的预训练网络RESNET-50[22],该网络可以达到76.15%的TOP-1准确率。所有模型都是使用Pytorch进行培训的,我们的源代码是公开提供的。
我们比较了以下几种算法:
1)基于OPT的黑盒攻击(OPT-Attack):我们提出的算法。
2)基于决策的黑盒攻击1:这是之前关于攻击硬标签黑盒模型的唯一工作。我们使用作者的实现并使用Foolbox中提供的默认参数。
3)C&W白盒攻击[9]:白盒环境下当前最先进的攻击算法之一。我们对每幅图像的参数进行二分查找,以达到最佳的性能。在白盒环境下攻击是一个容易得多的问题,所以我们包含C&W攻击仅供参考,并指出我们可能达到的最佳性能。
对于所有的情况,我们对验证集中随机抽样的N=100幅图像进行了对抗攻击。注意,这三种攻击都有100%的成功率,我们报告了平均$L_{2}$失真,定义为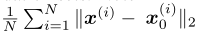 ,其中$x^{(i)}$是由攻击算法构造的对抗样本,$x_{0}^{(i)}$是原始样本,对于黑盒攻击算法,我们还报告了平均查询数以供比较。
,其中$x^{(i)}$是由攻击算法构造的对抗样本,$x_{0}^{(i)}$是原始样本,对于黑盒攻击算法,我们还报告了平均查询数以供比较。
4.1.1 非定向攻击(Untargeted attack)
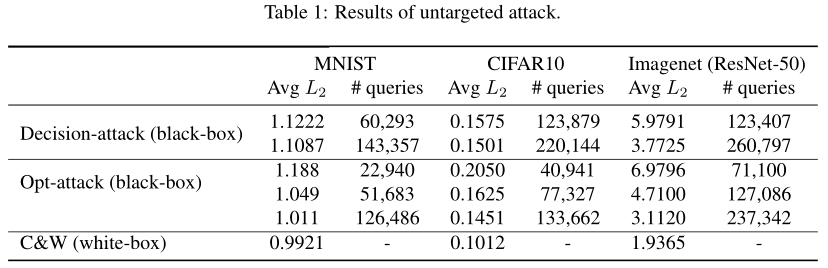
对于非目标攻击,目标是将正确分类的图像转换为任意其他标签。结果如表1所示,请注意,对于OPT攻击和Decision攻击,通过改变停止条件,我们可以得到不同数量的查询的性能。
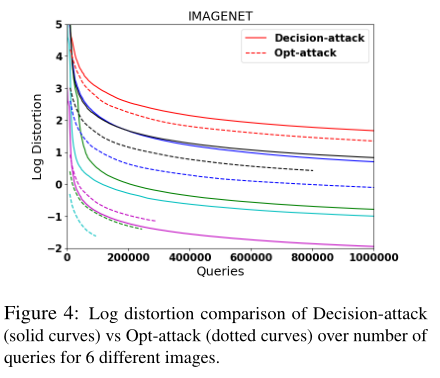
首先,我们比较了表1中的两种黑盒攻击方法。我们的算法始终比决策攻击用更少的查询数实现更小的失真。例如,对于 mnist 数据,我们可以减少3-4倍的查询次数,并且在所有3个数据集中,决策攻击收敛到更差的解。与 c & w 攻击相比,黑盒攻击对 mnist 和 cifar 的失真程度略有下降。这是合理的,因为白盒攻击比黑盒攻击有更多的信息,而且严格来说更容易。我们注意到,文献[1]中的实验结果表明,C&W攻击和决策攻击(Decision Attack)具有相似的性能,因为它们只运行带有单个正则化参数的C&W,而不进行二分查找来获得最优参数。对于 imageNet,由于我们限制了查询的数量,黑盒攻击的失真比C&W攻击严重得多。如图4所示,可以通过增加查询数量来缩小差距。
4.1.2 定向攻击(Targeted attack)
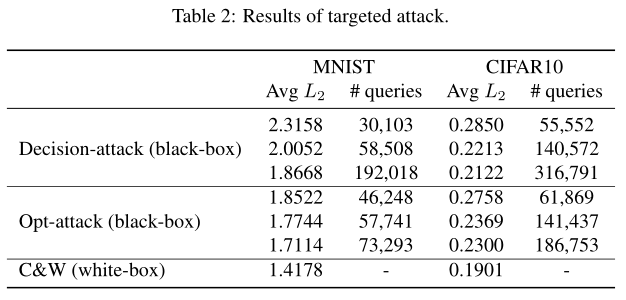
目标攻击的结果如表2所示。根据[1]中的实验,对于每个带有标签的随机采样图像,我们设置目标标签t=(i+1)mod10。在MNIST数据上,我们发现我们的算法比决策攻击算法快4倍以上(就查询次数而言),并且收敛到更好的解决方案。在CIFAR数据上,我们的算法与前60,000个查询的决策攻击算法具有相似的效率,但收敛到一个略差的解决方案。此外,我们在图5中显示了从相同起点到原始样本的质量比较示例。

4.1.3 攻击梯度增强决策树(GBDT)
为了评估我们的方法对离散决策函数模型的攻击能力,我们对梯度引导决策树(GBDT)进行了非定向攻击。在这个实验中,我们使用了两个标准数据集:Higgs[23]用于二分类,MNIST[19]用于多类分类。我们使用流行的LightGBM框架对GBDT模型进行训练。使用建议的参数,HIGGS的AUC值为0.8457,MNIST的准确率为98.09%。对GBDT的无针对性攻击结果如表3所示。
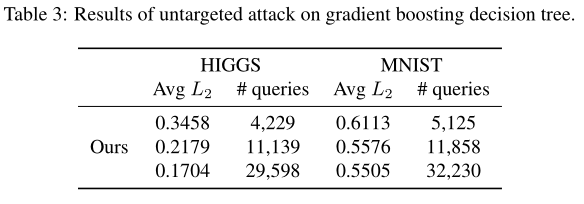
如表3所示,通过使用大约30K的查询,我们可以在两个数据集上得到一个小的失真,这首先揭示了GBDT模型的漏洞。基于树的方法以其良好的可解释性而闻名。正因为如此,它们在行业中得到了广泛的应用。然而,我们发现,即使GBDT模型具有良好的可解释性和与卷积神经网络相似的预测精度,在我们的OPT攻击下仍然是脆弱的。这一结果提出了一个关于基于树的模型的稳健性的问题,这将是未来一个有趣的方向。
5 结论
本文提出了一种通用的、基于优化的硬标签黑盒攻击算法,该算法适用于非神经网络的离散和非连续模型,如梯度增强决策树。该方法不仅具有查询效率,而且在攻击性能上有理论上的收敛保证。此外,与最先进的算法相比,我们的攻击使用的查询减少了3-4倍,从而实现了更小或相似的失真。
参考文献
[1]Wieland Brendel, Jonas Rauber, and Matthias Bethge. Decision-based adversarial attacks: Reliable attacks against
black-box machine learning models.arXiv preprint arXiv:1712.04248, 2017.
[2]Y urii Nesterov and Vladimir Spokoiny. Random gradient-free minimization of convex functions.F oundations of
Computational Mathematics, 17(2):527–566, 2017.
[3]Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples.arXiv
preprint arXiv:1412.6572, 2014.
[4]Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob
Fergus. Intriguing properties of neural networks.arXiv preprint arXiv:1312.6199, 2013.
[5]Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, Omar Fawzi, and Pascal Frossard. Universal adversarial
perturbations.
[6]Seyed Mohsen Moosavi Dezfooli, Alhussein Fawzi, and Pascal Frossard. Deepfool: a simple and accurate
method to fool deep neural networks. InProceedings of 2016 IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), number EPFL-CONF-218057, 2016.
[7]Hongge Chen, Huan Zhang, Pin-Y u Chen, Jinfeng Yi, and Cho-Jui Hsieh. Attacking visual language grounding
with adversarial examples: A case study on neural image captioning. InACL, 2018.
[8]Minhao Cheng, Jinfeng Yi, Huan Zhang, Pin-Y u Chen, and Cho-Jui Hsieh. Seq2sick: Evaluating the robustness of
sequence-to-sequence models with adversarial examples.CoRR, 2018.
[9]Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. InSecurity and Privacy
(SP), 2017 IEEE Symposium on, pages 39–57. IEEE, 2017.
[10]Pin-Y u Chen, Huan Zhang, Yash Sharma, Jinfeng Yi, and Cho-Jui Hsieh. Zoo: Zeroth order optimization based
black-box attacks to deep neural networks without training substitute models. InProceedings of the 10th ACM
Workshop on Artificial Intelligence and Security, pages 15–26. ACM, 2017.
[11]Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep
learning models resistant to adversarial attacks. InICLR, 2018.
[12]Pin-Y u Chen, Y ash Sharma, Huan Zhang, Jinfeng Yi, and Cho-Jui Hsieh. Ead: elastic-net attacks to deep neural
networks via adversarial examples. InAAAI, 2018.
[13]Andrew Ilyas, Logan Engstrom, Anish Athalye, and Jessy Lin. Query-efficient black-box adversarial examples.
arXiv preprint arXiv:1712.07113, 2017.
[14]Nicolas Papernot, Patrick McDaniel, Ian Goodfellow, Somesh Jha, Z Berkay Celik, and Ananthram Swami.
Practical black-box attacks against machine learning. InProceedings of the 2017 ACM on Asia Conference on
Computer and Communications Security, pages 506–519. ACM, 2017.
[15]Arjun Nitin Bhagoji, Warren He, Bo Li, and Dawn Song. Exploring the space of black-box attacks on deep neural
networks.arXiv preprint arXiv:1712.09491, 2017.
[16]Chun-Chen Tu, Pai-Shun Ting, Pin-Y u Chen, Sijia Liu, Huan Zhang, Jinfeng Yi, Cho-Jui Hsieh, and Shin-Ming
Cheng. Autozoom: Autoencoder-based zeroth order optimization method for attacking black-box neural networks.
CoRR, abs/1805.11770, 2018.
[17]Andrew R Conn, Katya Scheinberg, and Luis N Vicente.Introduction to derivative-free optimization, volume 8.
Siam, 2009.
[18]Saeed Ghadimi and Guanghui Lan. Stochastic first-and zeroth-order methods for nonconvex stochastic program-
ming.SIAM Journal on Optimization, 23(4):2341–2368, 2013.
[19]Yann LeCun, L´eon Bottou, Y oshua Bengio, and Patrick Haffner. Gradient-based learning applied to document
recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998.
[20]Alex Krizhevsky. Learning multiple layers of features from tiny images. 2009.
[21]Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image
database. InComputer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on, pages 248–255.
IEEE, 2009.
[22]Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In
Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
[23]Pierre Baldi, Peter Sadowski, and Daniel Whiteson. Searching for exotic particles in high-energy physics with
deep learning.Nature communications, 5:4308, 2014.
[24]Y urii Nesterov. Random gradient-free minimization of convex functions. Technical report, 2011.
回溯直线搜索
回溯直线搜索是求解无约束凸优化问题中,调整搜索步长非常简单有效的方法,也是实际应用中常用的方法。

友情链接
文件笔记:./【文献笔记】Query-Efficient-Hard-label-Black-box-Attack-An-Optimization-based-Approach
算法分析:./【算法】Opt-Attack算法手稿