0x00 原文链接以及源码链接
原文:https://arxiv.org/abs/1712.04248
源码:https://github.com/bethgelab/foolbox
0x01:应用场景
Decision-Based:不知道模型细节,只知道模型的最终分类结果。
0x02 提出的攻击方法:Boundary Attack
Boundary Attack:从一个大的对抗性扰动开始,然后试图在保持对抗性的同时减少扰动。
边界攻击算法背后的基本直觉如图2所示,该算法从一个已经是对抗性的点开始初始化,然后沿着对抗性区域和非对抗性区域之间的边界执行随机游走,使得:
(1)对抗样本停留在对抗性区域内;
(2)减少对抗样本到目标图像的距离。
换句话说,根据给定的对抗准则$c(\cdot)$,我们用一个合适的建议分布$P$执行拒绝抽样(rejection sampling,不懂。待查。),来找到逐渐变小的对抗扰动。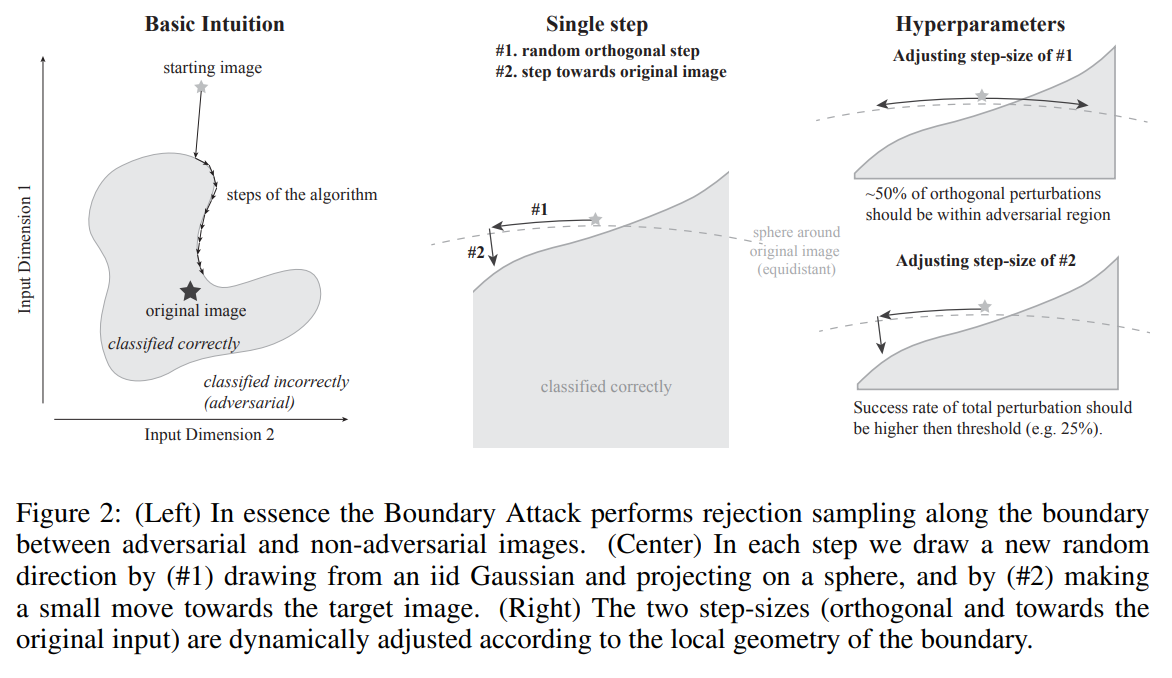
算法的基本逻辑在算法1中描述,每个单独的构建块将在下一小节中详细说明。
Algorithm 1:Minimal version of the Boundary Attack,如Algorithm 1所示:
算法的输入为:原始图像$o$,对抗规则$c(\cdot)$,目标模型预测$d(\cdot)$
结果: 获得和原始样本距离最小的对抗样本$\tilde{\boldsymbol{o}}$
0x02.1 初始化
边界攻击需要用已经是对抗性的样本进行初始化。在非定向攻击的情况下,我们只需从给定输入的有效域的最大熵分布中抽样。在下面的计算机视觉应用中,输入被限制在每个像素[0,255]的范围内,我们从一个均匀分布的$U$(0,255)中抽取初始图像$\tilde{\mathbf{o}}^{0}$中的每个像素。我们拒绝非敌对性的样本。在定向攻击设置中,我们从模型分类为目标类的任何样本开始。
0x02.2 建议分布
算法的效率很大程度上取决于建议的分布$P$,即在算法每一步所探索的随机方向。最优的建议的分布通常取决于要攻击的领域和/或模型。这个建议的分布背后的基本思想如下:在第k步中,我们希望从满足以下约束的最大熵分布中得出扰动$\eta^{k}$:
1)扰动样本位于输入域内
$\tilde{\mathbf{o}_{i}}^{k-1}+ \eta^{k}_{i}\in[0,255]$ (1)
2)扰动的相对大小为$\delta$
$\left | \eta^{k}\right |_{2}=\delta \cdot\ d({\mathbf{o}},\tilde{\mathbf{o}_{i}}^{k-1})$ (2)
3)该扰动将扰动图像相对于原始输入的距离减少了相对量$\epsilon$
$d({\mathbf{o}},\tilde{\mathbf{o}_{i}}^{k-1}) - d({\mathbf{o}},\tilde{\mathbf{o}_{i}}^{k-1} + \eta^{k}) = \epsilon \cdot d({\mathbf{o}},\tilde{\mathbf{o}_{i}}^{k-1})$
在实践中,很难从该分布中采样,因此我们求助于一个更简单的启发式方法:
首先, 我们从一个iid高斯分布$\eta^{k}_{i}$~$N(0,1)$中采样,然后重新缩放和剪裁,使得(1)和(2)成立。
第二步,我们把$\eta^{k}$投影到围绕原始图像$o$的球面上,使得 $ d({\mathbf{o}},\tilde{\mathbf{o}_{i}}^{k-1} + \eta^{k}) = d({\mathbf{o}},\tilde{\mathbf{o}_{i}}^{k-1})$和(1)成立。 我们将其表示为正交扰动,稍后将其用于超参数调谐。
最后一步中,我们向原始图像做一个小的移动,使得(1)和(3)保持不变。
对于高维输入和小的$\delta$、$\epsilon$,约束(2)也将大致成立。
0x02.3 对抗标准
非定向攻击(Untargeted Attack):指鹿不为马
定向攻击(Target Attack):指鹿为马
top-k分类错误:目标模型输出的top-k类不包括真实类别;
置信度阈值:目标模型对特定类输出的置信度达到阈值。
0x02.4 超参数调整
边界攻击只有两个相关参数:总扰动$\delta$的长度和朝向原始输入的步骤$\epsilon$的长度(见图2)。
我们根据边界的局部几何形状动态调整这两个参数。这次调整的灵感来自于信任域方法(Trust Region methods)。 本质上,我们首先测试正交扰动是否仍然是对抗性的。如果这是true,那么我们向目标移动一小步,然后再测试一次。正交步长检验步长是否足够小,以便我们可以将对抗性区域和非对抗性区域之间的决策边界视为近似线性的。如果是这样的话,我们预计大约50%的正交扰动仍然是对抗性的。如果这个比率低得多,我们就减小步长$\delta$,如果它接近50%或更高,我们就增大它。如果正交扰动仍然是对抗性的,我们向原始输入增加一小步。此步骤的最大大小取决于局部邻域中决策边界的角度(另请参见图2)。如果成功率太小,我们会减少$\epsilon$如果成功率太大,我们会增加$\epsilon$。通常,我们离原始图像越近,决策边界就越平坦,而$\epsilon$越小才能继续取得进展。只要$\epsilon$收敛到零,攻击就会收敛。
0x03 与其他攻击的比较
我们量化了边界攻击在三个不同标准数据集上的性能:MNIST、CIFAR-10和ImageNet-1000。为了尽可能简单和透明地与以前的结果进行比较,我们在这里使用与Carlini&Wagner相同的MNIST和CIFAR网络。简而言之,MNIST和CIFAR模型都有9层,包括4个卷积层、2个最大汇聚层和2个完全连通层。在ImageNet上,我们使用Keras5提供的预先训练的网络VGG-19、ResNet-50和Inception-v3。
我们在两种设置中评估边界攻击: (1)非定向攻击设置,其中对抗性的扰动将原样本的标签翻转到任何其他标签; (2)定向攻击设置,其中对抗性的扰动将标签翻转到特定的目标类。
在非目标环境下,我们比较了三种基于边界的攻击算法:
Fast-Gradient Sign Method(FGSM):FGSM是最简单、应用最广泛的非定向对抗攻击方法之一。简而言之,FGSM计算梯度$g=\nabla_{o} \mathcal{L}(\boldsymbol{o}, c)$,该梯度使真实类标签$c$的损失$\mathcal{L}$的损失最大,然后寻找使$\boldsymbol{o} + \epsilon \cdot \mathcal{g}$仍然保持对抗性的最小$\epsilon$。
DeepFool:DeepFool是一种简单但非常有效的攻击。在每次迭代中,它通过用线性分类器近似模型分类器,为每个类$\ell \neq \ell_{0}$计算到达类边界所需的最小距离$d(\ell,\ell_{0})$。然后,它在距离最小的类的方向上进行相应的步骤。
Carlini & Wagner:Carlini&Wagner的攻击本质上是一种改进的迭代梯度攻击,它使用Adam优化器、多起点、考虑盒约束的tanh非线性和基于最大值的对抗约束函数。
为了评估每次攻击的成功程度,我们使用以下指标:
设$\boldsymbol{\eta}_{A, M}\left(\boldsymbol{o}_{i}\right) \in \mathbb{R}^{N}$为攻击$A$对第$i$个样本$o_{i}$在模型M上发现的对抗性扰动。$A$的总分$S_{A}$是所有样本上$L_{2}$距离的中位数平方,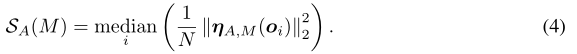
对于MNIST和CIFAR,我们评估从验证集中随机抽取的1000个样本,对于ImageNet,我们使用250个图像。
0x03.1 非定向攻击
在非定向攻击设置中,对抗性是其预测标签与原始图像的标签不同的任何图像。我们在图3中显示了通过边界攻击为每个数据集合成的对抗性样本。每个攻击和每个数据集的得分如下:
尽管边界攻击很简单,但就最小的对抗性扰动而言,它与基于梯度的攻击具有竞争性,并且对于初始点的选择非常稳定(图5)。
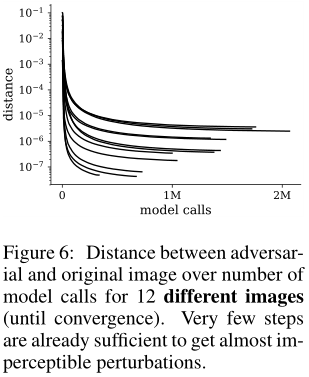
这一发现相当值得注意,因为基于梯度的攻击可以完全观察到模型,而边界攻击则严格限制在最终类预测上。为了弥补这种信息的缺乏,边界攻击需要更多的迭代才能收敛。作为与实现质量无关的攻击运行时间的粗略衡量标准,我们跟踪了每个攻击请求通过网络的向前传递(预测)和向后传递(梯度)的数量,以找到Resnet-50的对手:平均超过20个样本,在与以前相同的条件下,DeepFool需要大约7个向前传递和37个向后传递,Carlini&Wagner攻击需要16000个向前传递和相同数量的向后传递,边界攻击使用1200000个向前传递但0个反向传递。虽然这(毫不奇怪)使得边界攻击的运行成本更高,但重要的是要注意,如果人们只对不可察觉的扰动感兴趣,边界攻击需要的迭代次数要少得多,请参见图4和图6。
0x03.2 定向攻击
我们也可以在有目标的情况下使用边界攻击。在这种情况下,我们从模型正确识别的目标类样本中初始化攻击。从起点到原始样本的样本轨迹见图7。
对模型进行大约$10^{4}$次调用之后,受干扰的图像已经被人类清楚地识别为猫,并且没有达尔马提亚狗的痕迹,但这张照片仍然被模型分类为斑点狗。
为了将边界攻击与Carlini&Wagner进行比较,我们以如下方式为每个样本定义了目标目标标签:在MNIST和CIFAR数据集中,标签为$\ell$的样本得到的目标标签是($\ell+1$ )mod 10。在ImageNet上,我们随机绘制目标标签,但在各种攻击中保持一致的。结果如下: